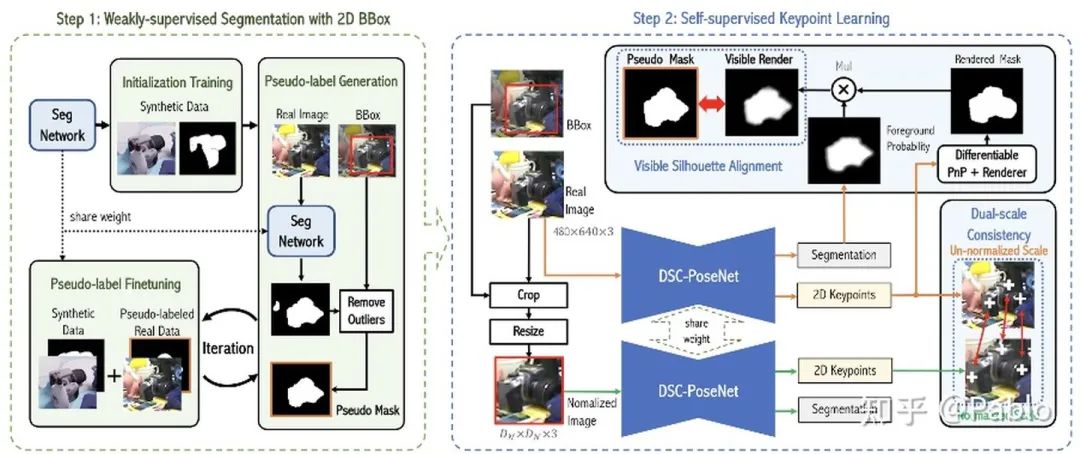
无序不规则数据挑战
这类数据缺乏秩序,与遵循有序规则像素网格的图像存在差异。它们以点颜色等属性为特征,并以键值对的形式呈现。对于深度神经网络来说,处理这种数据极具挑战,现有方法难以奏效,亟需创新技术和算法来应对。
面对无序和不规则的数据,传统方法因为缺少明确的框架,难以提取有效特征,进而分析能力受限,结果模型的表现显著下滑。
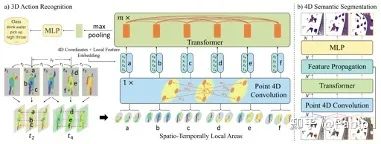
Transformer 技术应用
相关论文应用了Transformer这种非局部技术。这种技术能够避免直接追踪点,有效解决了无序和不规则数据的处理难题。还有一种技术是构建时空层次结构,例如在 ICLR2021 会议上发表的 PSTNet 论文中介绍的方法。
Transformer凭借其特有的关注机制,有效识别数据间的远距离关联,增强了处理无序和不规则数据的能力,在实验中显现出明显优势。
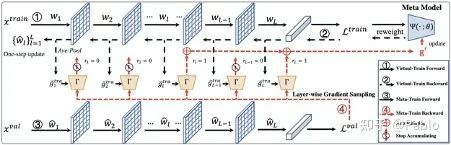
自适应梯度计算

根据sampler的输出结果,模型在训练阶段能够自动决定是否计算并搜集该层网络的梯度。这一自动调整机制有助于提升训练的效率,并增强模型的性能。
自适应梯度算法能减少冗余计算,降低资源消耗,并让模型更集中处理重要信息,在处理复杂数据时表现尤为出色。
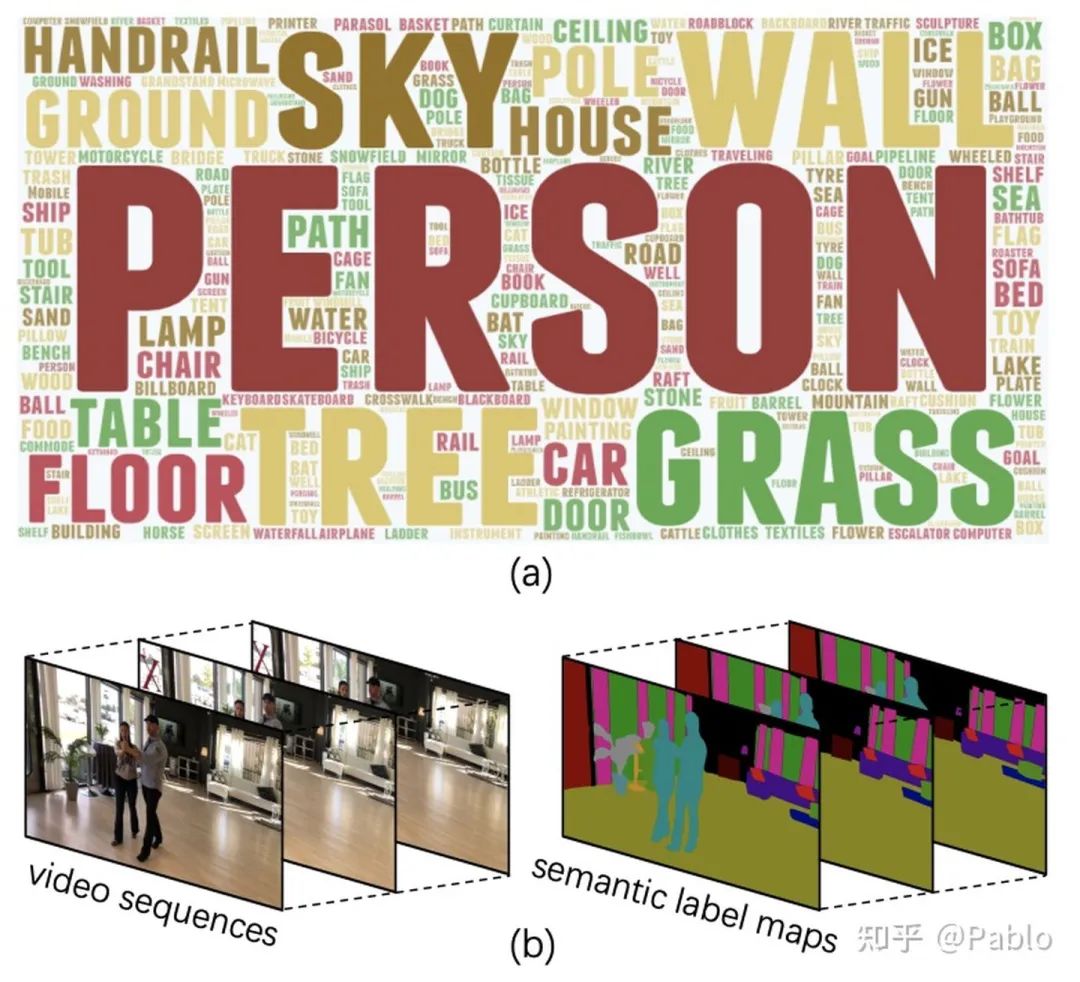
视频语义分割困境
近些年,图像语义分割技术进步迅猛,但视频语义分割的研究相对较少。这主要是因为缺乏足够大的视频语义分割数据集,这限制了相关领域的研究和技术进步。
缺乏充足的大规模数据集,模型难以充分掌握特征和模式,这影响了视频语义分割的精确度和普遍适用性。
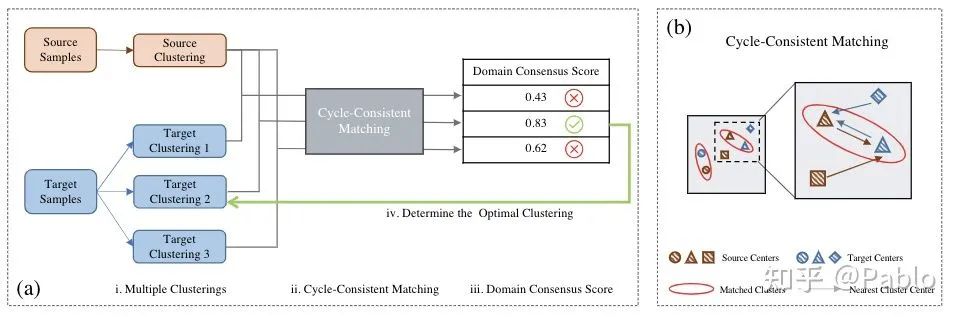
域共识聚类方法

为了解决视频语义分割所需数据集短缺的问题,我们提出了一种域共识聚类的新方法。这种技术能够同时处理已知类别和未知类别,从而在隐含空间中有效地挖掘出有用信息。
在语义分析中,我们通过比较源域和目标域的最近邻聚类,来识别可能存在的共同类别。这样做,增强了我们对跨领域数据处理的效能。
OpenMix 方法创新
文章介绍了 OpenMix 技术,该方法将已标记样本与未标记样本进行混合处理。同时,它将这两类样本的标签在联合标签分布中进行混合,从而提高了模型对新型类别识别的精确度。
选取样本中的若干作为基准,与其它样本结合,从而在新增类别中生成了更多样化的样本,这些样本有助于模型训练,进而提升了模型的广泛适用性。
众人都在探讨,在图像与视频的语义分割领域,哪种技术有望实现重大突破?