
浏览某个短视频网站时,常常会遇到想保存的视频不能下载,或者下载后带有水印的问题,这确实挺让人烦恼。实际上,我们可以编写一个程序来去除水印并下载视频,下面我会详细说明这个过程。
问题背景
在使用某短视频平台浏览时,大家或许都曾遇到心仪的视频,渴望将其保存至本地。然而,有些视频无法下载,有些则因水印而影响观看体验。无论是用于收藏还是作为动态壁纸,这样的效果都大不如前。因此,开发一款能够去除水印并下载视频的程序显得尤为迫切。
这款短视频平台颇受欢迎,每日活跃用户数以亿计,众多用户希望保存视频,这一需求促使开发相应的应用程序变得尤为迫切。
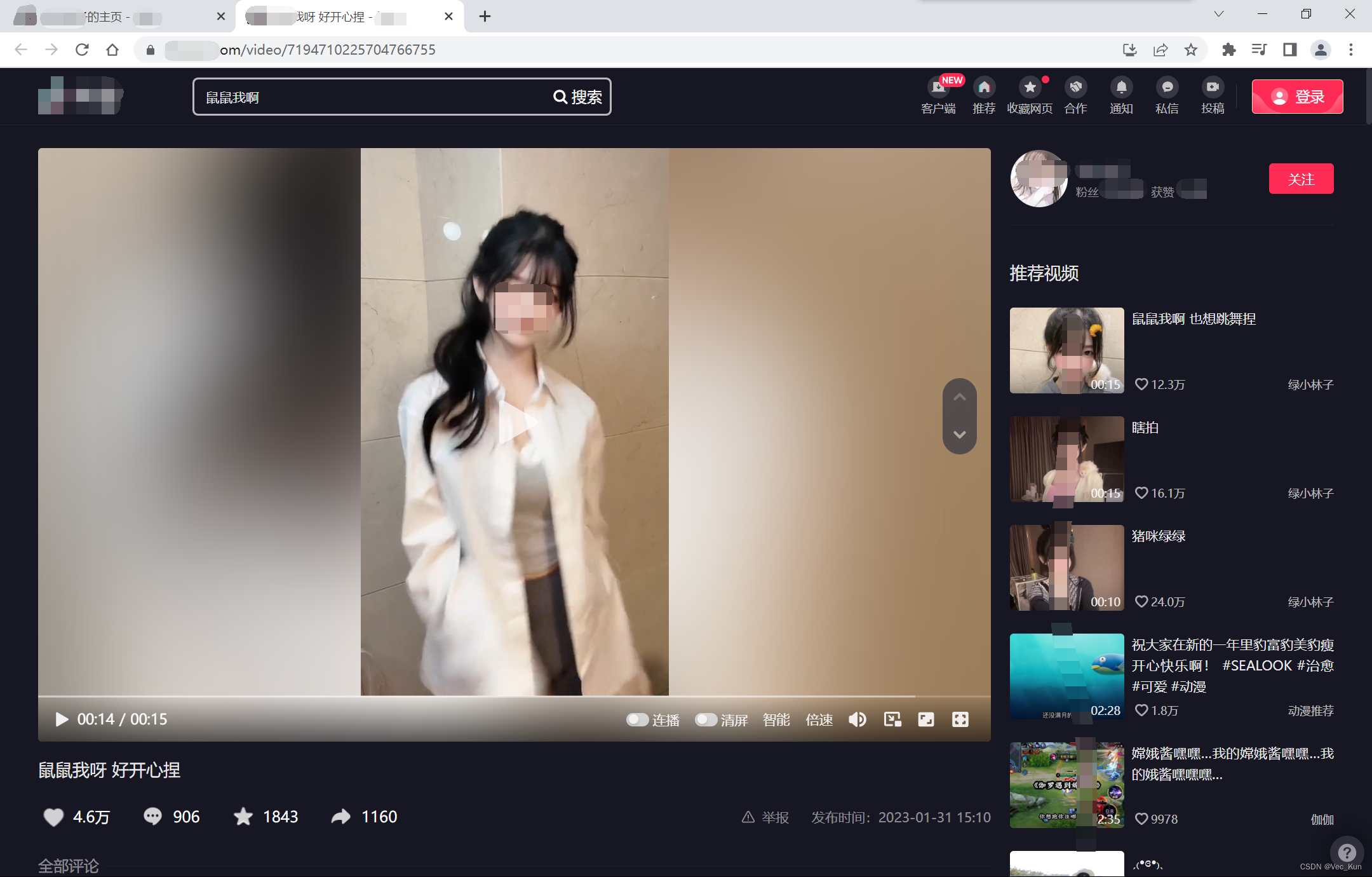
请求URL查看源代码
实现去水印下载的首要步骤是向指定网址发送请求,并浏览其源代码。在发送请求时,必须添加必要的请求头信息,以进行伪装,其中Cookie和User-Agent信息至关重要。成功伪装后访问主页,需检查相关元素,确认视频是否已嵌入源代码中。通常情况下,视频并不在源代码中,这暗示视频可能位于其他位置。
url = '见评论区'
headers = {
'cookie': 'douyin.com; __ac_nonce=063d749310021f8bd394b; __ac_signature=_02B4Z6wo00f01R8urHgAAIDBnyxWOmwmfMUfDqjAACQfd6; ttwid=1%7CtRZY98IpvYfhjM-VRDQHgX3mgPcfWwWxylxnwwC7fFk%7C0%7C9af2c384c7d2b4e10ec0497fce797af996c72dd3868ec040595de36132c01ad0; home_can_add_dy_2_desktop=%220%22; passport_csrf_token=ee0cbadbf97ac430daac207c46997ca1; passport_csrf_token_default=ee0cbadbf97ac430daac207c46997ca1; strategyABtestKey=%221675053365.079%22; s_v_web_id=verify_ldibiwgl_ycqaypzT_aJxd_4ZEW_9iGD_XkAPFGlhzwd3; AB_LOGIN_GUIDE_TIMESTAMP=%221675053363589%22; msToken=L3xfxnCP4kW9_qabjW3S1cud_5DmI99tIEOw1_lJDMgdp1GJ9KQd6HWXKepYY-7iLlj4SR_V02zL3lYO6FVnXoPPVNneC5bD9cEnYN4nNpXzaNmvq7oA; ttcid=a598309ef5f3442b95f1d979574083f925; tt_scid=Px0Q21O38QIdeziR7nBXUqfZYJaS4qKakt5Zkfio72r9U4XaJdOYTb37LsjIrRLQca96; msToken=xibNm7RgEpzX8c6UaAgkzAOHMr5TcWNmNbfFR1vD-3uNUhtRXEqVQrmPIV6iDsnsA3WhMCTIOGDtST_F9GEyq8In6Dj7ug-RXsQ6dWDIjzE3OXKr5dlj',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36'
}
resp = requests.get(url=url, headers=headers)这一环节对咱们找视频源头至关重要,若视频直接嵌入代码里,后续的工作会轻松不少。但实际情况往往不尽如人意,许多信息还需深入挖掘。
使用抓包工具
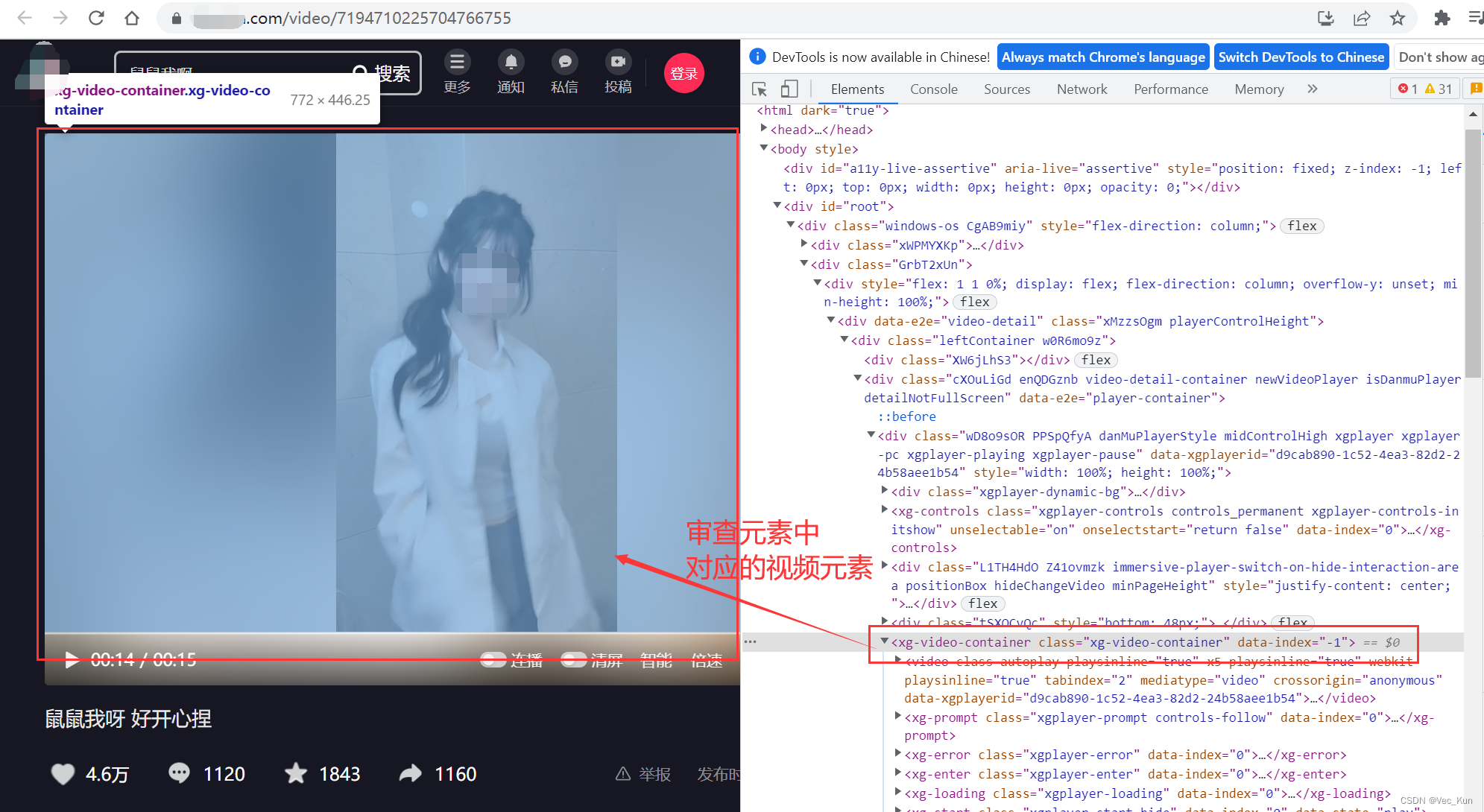
若源代码内缺失视频内容,便需运用抓包软件。此类软件能捕捉网页与服务器间的数据交换,揭示隐藏的视频资源链接。常见的抓包软件有Charles和Fiddler等。在浏览视频页面时,抓包软件会记录下所有数据传输。在这些大量数据中,我们需筛选出与视频相关的部分,进而找到视频源链接。
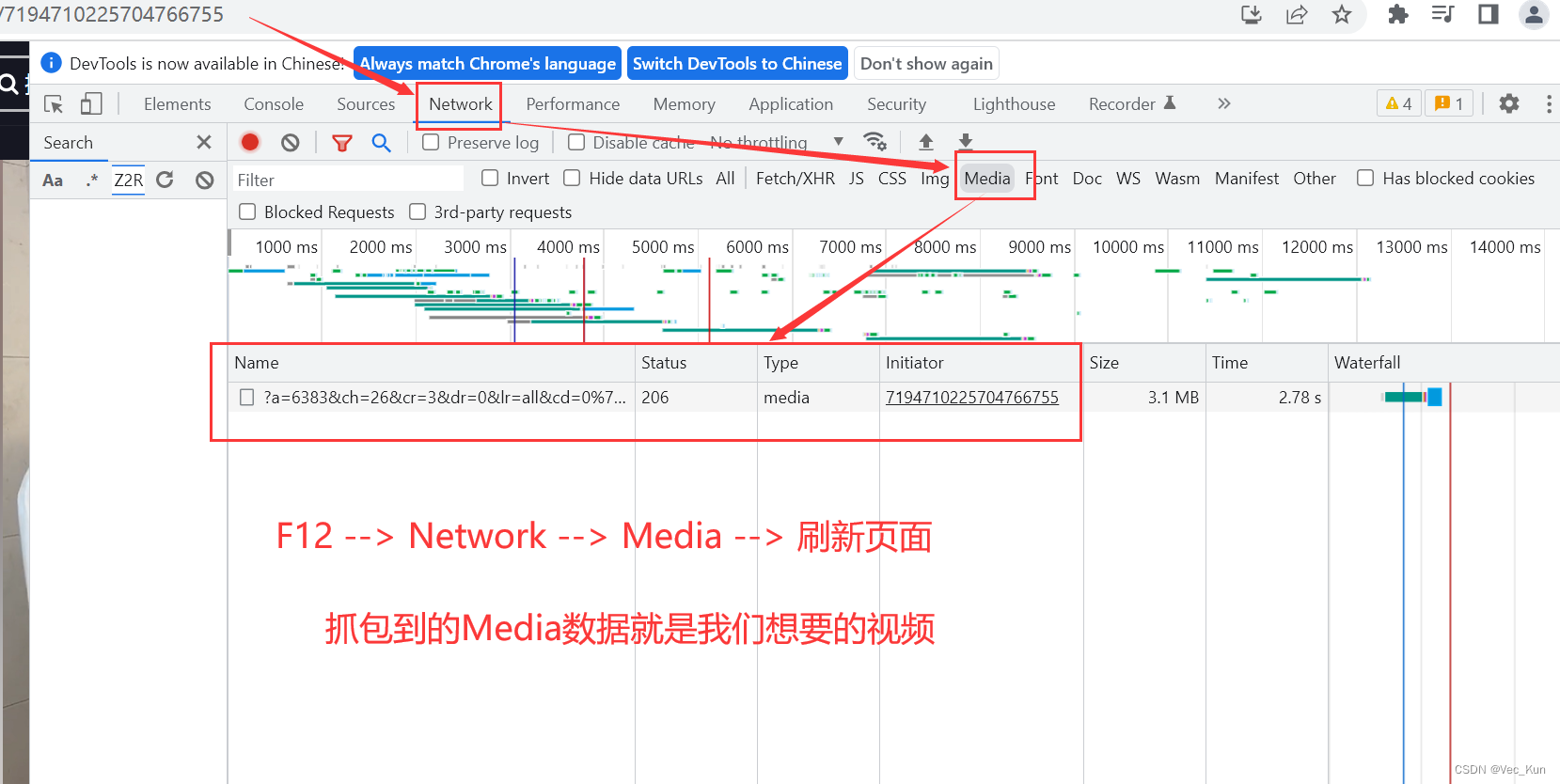
这个过程宛如在茫茫大海中寻找一根针,这要求我们具备耐心和一定的技巧。然而,只要我们成功找到视频的链接,那么下载去水印视频的目标就近在咫尺了。
检索视频源链接来源
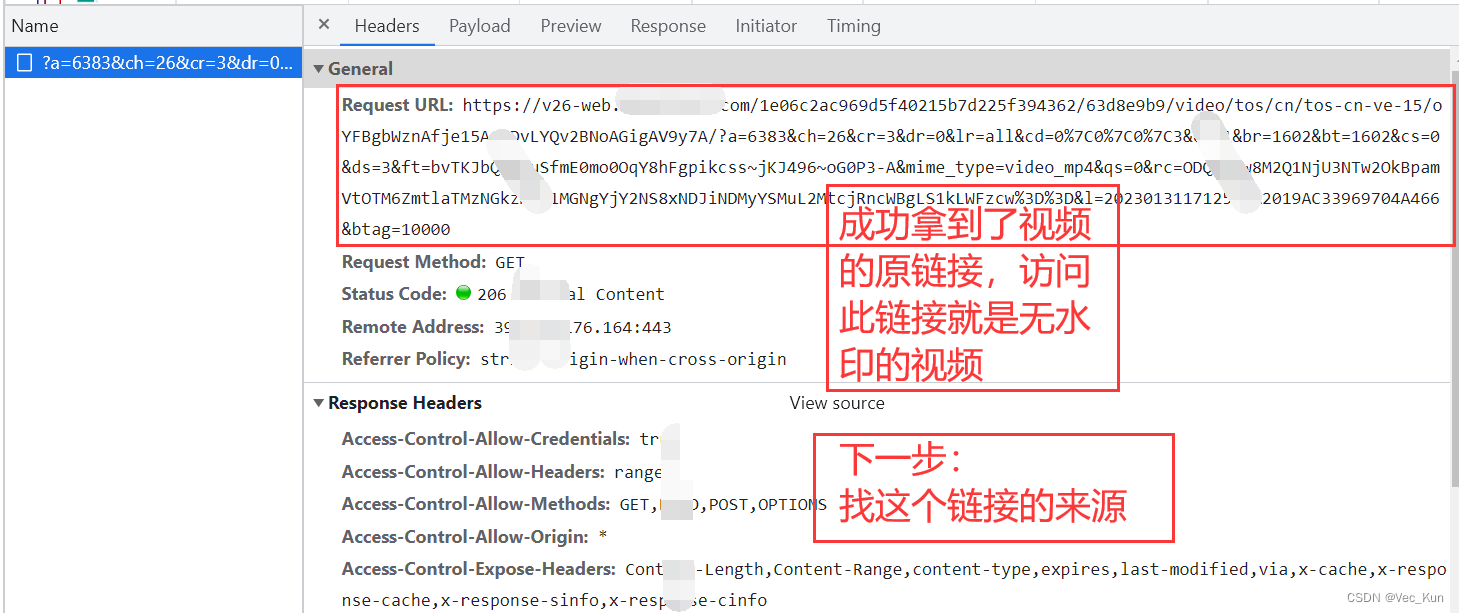
获取视频链接后,不可急于下载,必须先查明其出处。这是保证下载视频稳定且无水印的关键环节。需对视频链接的网址及参数进行深入分析,以便掌握视频的存储和编码方式。有时,视频链接可能涉及多级跳转和加密,我们必须逐步破解这些难题。
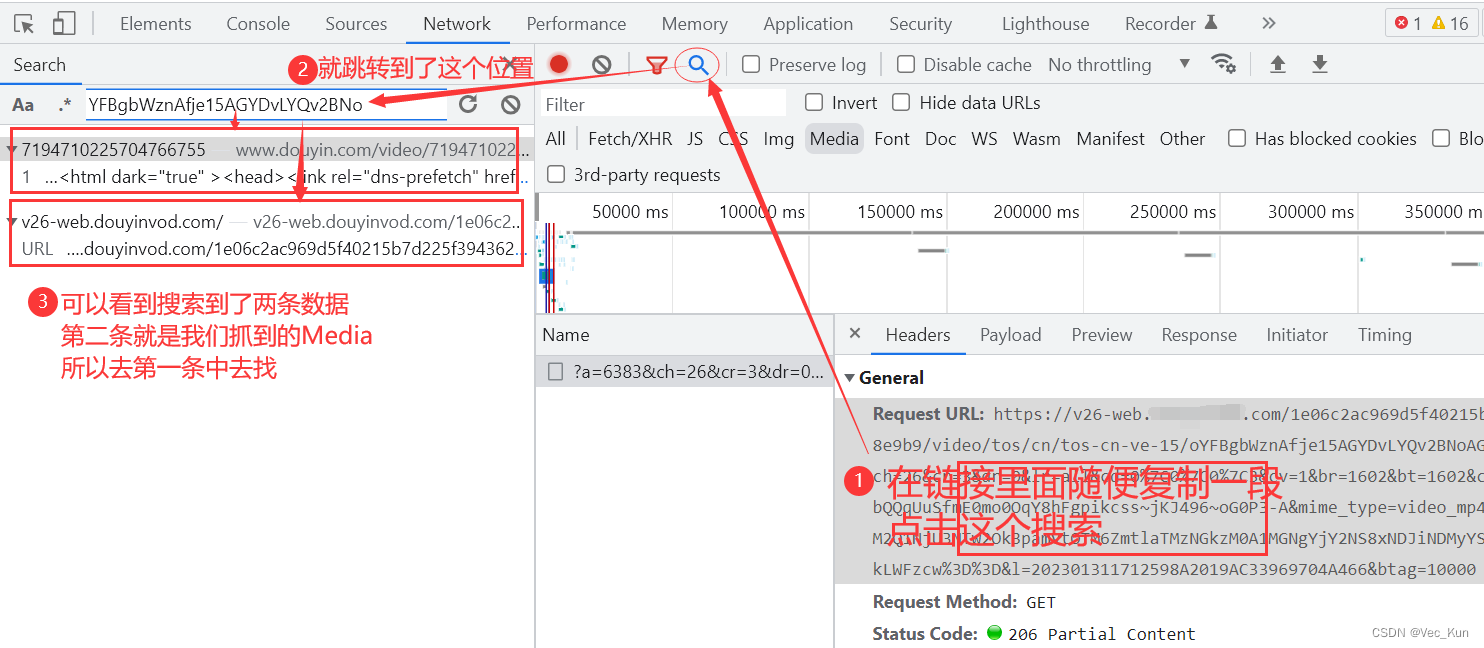
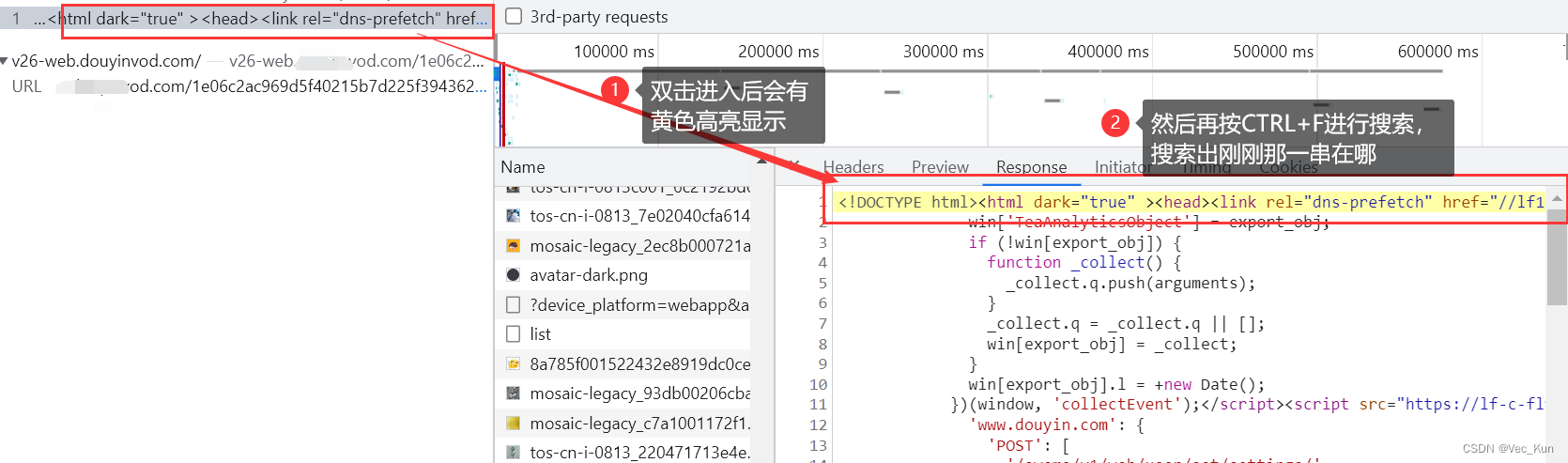
某些短视频网站会对视频链接执行时间戳及签名双重核实,只有成功通过这两项检查,用户才能顺利下载到无任何水印的完整视频。
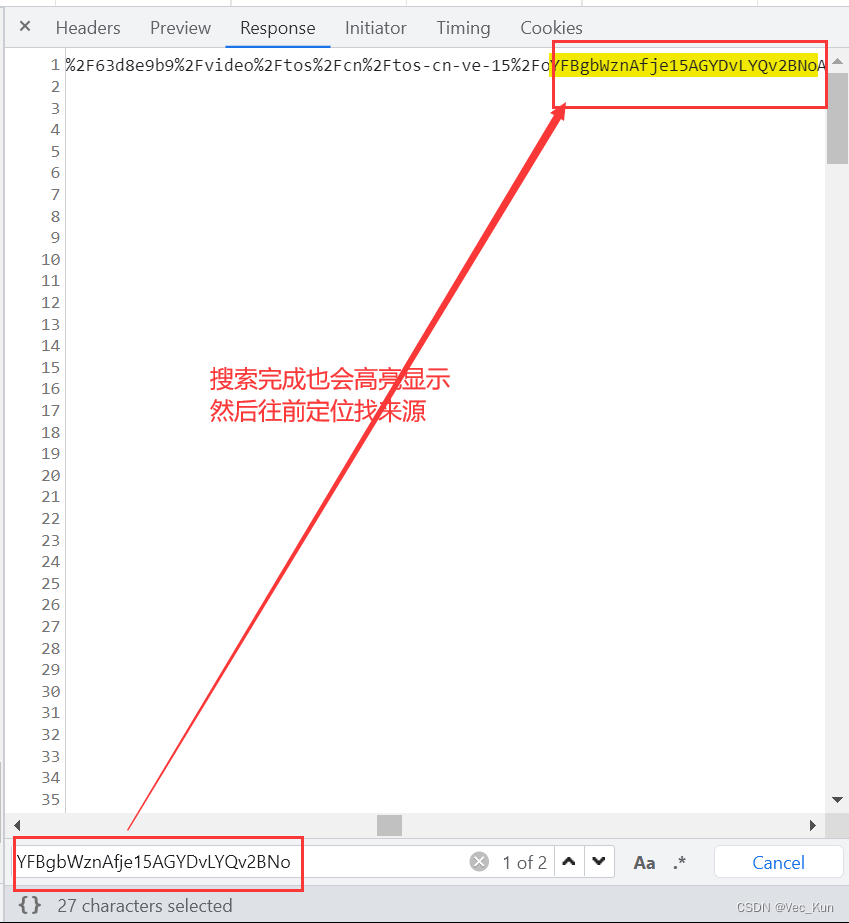
数据处理与本地保存
获取到有用的视频资料和网址后,接下来的步骤是将这些资料以二进制格式保存在本地。我们可以通过使用编程语言提供的文件处理功能来实现这一点。在保存之前,我们可以用正则表达式提取视频的名称,并将其作为本地保存文件的名称,这样做可以让保存的视频更容易被识别。
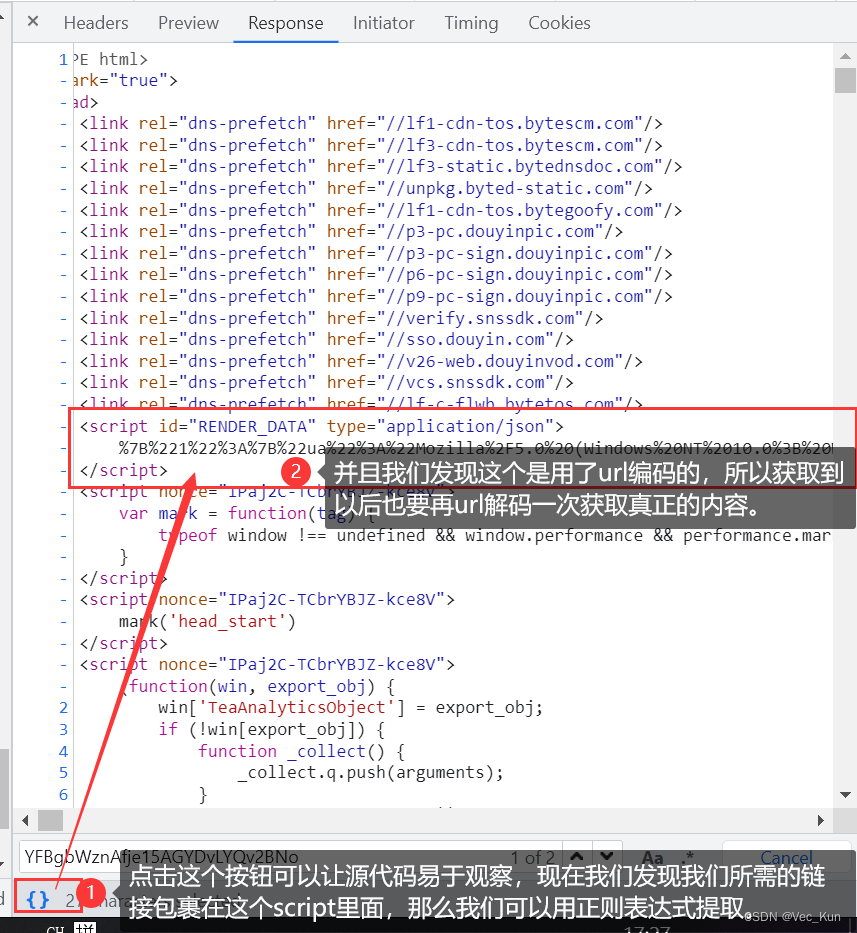
通过正则表达式提取出script标签内的视频内容,解码后,运用pprint工具将信息以美观的格式展示,观察其规律,定位视频链接的具体位置。最终,将视频文件保存在设定的本地目录中,实现下载任务。
实战总结
这次实践让我们全面体验了某短视频平台视频去水印的全过程。从发起URL请求,到运用抓包工具、查找视频源、处理数据并将其保存在本地,这一过程涵盖了爬虫的多个知识点,如伪装请求头、运用正则表达式、文件操作等。这算是一次全面的训练,非常适合加强爬虫基础知识的掌握。
# 正则抓标题
obj = re.compile(r"(?P.*?)</span></span></span></span>", re.S)
title = obj.search(resp.<a href='https://new.asjzyw.com/post/1830.html' title='text' target='_blank'>text</a>).group("title")
# print(title)
# 正则抓视频信息
info = re.findall('<script id="RENDER_DATA" type="application/json">(.*?)</script', resp.text)[0]
# print(info)
# url解码
html_data = urllib.parse.unquote(info)
html_data = json.loads(html_data)
# pprint(html_data) # 让字典更加美观
# 字典取值,拿视频播放链接
video_url = 'https:' + html_data['41']['aweme']['detail']['video']['bitRateList'][0]['playAddr'][0]['src']
print(video_url)</code></pre></p>
<p class="quietlee_6ea9a_b1baa">大家可以琢磨琢磨,在使用抓包软件时,面对那些加密难度极高的数据,还有什么更快捷的破解途径?欢迎在评论区留言交流,同时也请点赞并转发这篇文章,让更多有需求的人能够看到。</p></div> </div>
</div>
<footer class="entry-footer quietlee_4324f_737d7">
<div class="post-tags quietlee_bea93_03d25"><a href="https://new.asjzyw.com/tags-1912.html" rel="tag" title="查看标签为《text》的所有文章">text</a><a href="https://new.asjzyw.com/tags-2803.html" rel="tag" title="查看标签为《code》的所有文章">code</a></div> <div class="readlist ds-reward-stl quietlee_82079_9dc51">
<div class="read_outer zanter quietlee_64db8_07e1e" title="打赏">
<p class="dasbox quietlee_9d391_6768a"><a href="javascript:;" onclick="reward()" class="dashang" title="打赏,支持一下"><i class="fa fa-yen"></i> 打赏</a></p>
</div> <div class="read_outer quietlee_c5259_e5c3a"><a class="read" href="javascript:;" title="阅读模式"><i class="fa fa-send"></i> 阅读</a></div>
<div class="read_outer quietlee_34173_cb38f"><a class="comiis_poster_a" href="javascript:;" title="生成封面"><i class="fa fa-image"></i> 海报</a></div>
<div id="mClick" class="mobile_click quietlee_c3513_47f02">
<div class="share quietlee_3c624_dd3c6">
<div class="Menu-item quietlee_3d11a_e629e"><a href="javascript:Share('tqq')"><i class="fa fa-qq"></i> QQ 分享</a></div>
<div class="Menu-item quietlee_c16a5_320fa"><a href="javascript:Share('sina')"><i class="fa fa-weibo"></i> 微博分享</a></div>
<div class="Menu-item quietlee_6364d_3f0f4"><i class="fa fa-weixin"></i> 微信分享<img alt="微信扫一扫" src="https://new.asjzyw.com/zb_users/theme/quietlee/plugin/api.php?url=https://new.asjzyw.com/qt/2122.html"></div>
</div>
<i class="fa fa-share" title="分享转发"></i> 分享
</div> </div>
</footer>
</article>
<nav class="single-nav quietlee_67d25_2f75a"> <div class="entry-page-prev j-lazy quietlee_3b371_62594" style="background-image: url(https://new.asjzyw.com/zb_users/theme/quietlee/style/noimg/1.jpg)">
<a href="https://new.asjzyw.com/pdd/2121.html" title="拼多多进不去?三大原因揭秘,你中招了吗"><span>拼多多进不去?三大原因揭秘,你中招了吗</span></a>
<div class="entry-page-info quietlee_71ce8_fb1fb"><span class="pull-left">« 上一篇</span><span class="pull-right">2025-02-05</span></div>
</div>
<div class="entry-page-next j-lazy quietlee_754a5_24899" style="background-image: url(https://new.asjzyw.com/zb_users/theme/quietlee/style/noimg/1.jpg)">
<a href="https://new.asjzyw.com/qt/2123.html" title="DNF卡特:你的游戏升级神器,真的能让你轻松完成所有任务吗?"><span>DNF卡特:你的游戏升级神器,真的能让你轻松完成所有任务吗?</span></a>
<div class="entry-page-info quietlee_182be_0c5cd"><span class="pull-right">下一篇 »</span><span class="pull-left">2025-02-05</span></div>
</div>
</nav>
<div class="part-mor quietlee_9c626_5cc5f"><!--相关文章-->
<h3 class="section-title"><span><i class="fa fa-rss-square"></i>相关阅读</span></h3>
<ul class="section-cont-tags pic-box-list clearfix">
<!--相关标签-->
<li class="quietlee_2cfb7_60fe3"><a href="https://new.asjzyw.com/dy/2184.html"><i class="pic-thumb"><img class="lazy" src="https://new.asjzyw.com/zb_users/upload/2025/06/1738821896172_0.png" alt="抖音运营培训班完美落幕!浠水县70名学员如何掌握网红经济新技能?" title="抖音运营培训班完美落幕!浠水县70名学员如何掌握网红经济新技能?"></i>
<h3>抖音运营培训班完美落幕!浠水县70名学员如何掌握网红经济新技能?</h3>
<p class="quietlee_e3698_53df7"><b class="datetime">2025-02-06</b><span class="viewd">40 人在看</span></p>
</a></li>
<li class="quietlee_1c383_cd30b"><a href="https://new.asjzyw.com/post/1912.html"><i class="pic-thumb"><img class="lazy" src="https://new.asjzyw.com/zb_users/upload/2025/03/1738577357160_0.jpg" alt="想成为抖音快手达人吗?这个岗位等你来撩" title="想成为抖音快手达人吗?这个岗位等你来撩"></i>
<h3>想成为抖音快手达人吗?这个岗位等你来撩</h3>
<p class="quietlee_19ca1_4e7ea"><b class="datetime">2025-02-03</b><span class="viewd">43 人在看</span></p>
</a></li>
<li class="quietlee_a5bfc_9e079"><a href="https://new.asjzyw.com/qt/1833.html"><i class="pic-thumb"><img class="lazy" src="https://new.asjzyw.com/zb_users/upload/2025/02/1738505591210_0.png" alt="中国考古博物馆文创店开业!200余种产品背后藏着什么?" title="中国考古博物馆文创店开业!200余种产品背后藏着什么?"></i>
<h3>中国考古博物馆文创店开业!200余种产品背后藏着什么?</h3>
<p class="quietlee_a5771_bce93"><b class="datetime">2025-02-02</b><span class="viewd">36 人在看</span></p>
</a></li>
<li class="quietlee_d67d8_ab4f4"><a href="https://new.asjzyw.com/post/1830.html"><i class="pic-thumb"><img class="lazy" src="https://new.asjzyw.com/zb_users/upload/2025/02/1738501950350_0.gif" alt="短视频异军突起,它到底带给我们什么?!" title="短视频异军突起,它到底带给我们什么?!"></i>
<h3>短视频异军突起,它到底带给我们什么?!</h3>
<p class="quietlee_d6459_20e39"><b class="datetime">2025-02-02</b><span class="viewd">38 人在看</span></p>
</a></li>
</ul>
</div>
<a href="https://new.asjzyw.com/pdd/2121.html" class="prev-article" title="拼多多进不去?三大原因揭秘,你中招了吗">
<i class="fa fa fa-angle-left"></i>
</a><a href="https://new.asjzyw.com/qt/2123.html" class="next-article" title="DNF卡特:你的游戏升级神器,真的能让你轻松完成所有任务吗?">
<i class="fa fa fa-angle-right"></i>
</a> </div>
<aside class="side fr quietlee_f0f95_16b40">
<section class="widget abautor quietlee_ff9f7_0eff6">
<div class="widget-list quietlee_50ad6_e4cbe">
<div class="widget_avatar quietlee_bd617_2d534" style="background-image: url(https://img.t.sinajs.cn/t5/skin/public/profile_cover/015_s.jpg);"><a href="https://new.asjzyw.com/author-1.html"><img class="widget-about-image" src="https://new.asjzyw.com/zb_users/avatar/0.png" alt="贝贝佳" height="70" width="70"><div class="widget-cover vip1 quietlee_e9dd0_5a44a"></div><i title="管理员" class="author-ident author1"></i></a></div>
<div class="widget-about-intro quietlee_2049e_d072d">
<div class="name quietlee_b208a_98582"><h3>贝贝佳</h3><span class="autlv aut-1 vs">V</span><span class="autlv aut-1">管理员</span></div>
<div class="widget-about-desc quietlee_25986_43494">文章 3306 篇 <i>|</i> 评论 0 次</div>
<div class="widget-article-newest quietlee_ffe7f_7e810"><span>最新文章</span></div>
<ul class="widget-about-posts">
<li class="quietlee_3416a_75f4c"><span class="widget-posts-meta">03/21</span><a class="widget-posts-title" href="https://new.asjzyw.com/dy/3322.html" title="还在为抖音小屏幕烦恼?教你如何轻松投屏到电视,享受大屏观感">还在为抖音小屏幕烦恼?教你如何轻松投屏到电视,享受大屏观感</a></li> <li class="quietlee_a1d0c_6e83f"><span class="widget-posts-meta">03/21</span><a class="widget-posts-title" href="https://new.asjzyw.com/post/3321.html" title="2023年创业新风口!好省短剧CPS项目如何让你快速赚大钱?">2023年创业新风口!好省短剧CPS项目如何让你快速赚大钱?</a></li> <li class="quietlee_17e62_166fc"><span class="widget-posts-meta">03/21</span><a class="widget-posts-title" href="https://new.asjzyw.com/pdd/3320.html" title="拼多多店铺三级惩罚交了保证金就能解封吗?商家们如何避免高额罚款?">拼多多店铺三级惩罚交了保证金就能解封吗?商家们如何避免高额罚款?</a></li> </ul> </div>
</div>
</section>
<section class="widget wow fadeInDown quietlee_a87dd_53d5f" id="divCatalog">
<h3 class="widget-title"><i class="fa fa-divCatalog"></i><span>网站分类</span></h3>
<ul class="widget-box divCatalog"><li class="quietlee_f7177_163c8"><a title="快手资讯" href="https://new.asjzyw.com/category-1.html">快手资讯</a></li>
<li class="quietlee_6c834_9cc72"><a title="抖音资讯" href="https://new.asjzyw.com/category-2.html">抖音资讯</a></li>
<li class="quietlee_d9d4f_495e8"><a title="拼多多资源" href="https://new.asjzyw.com/category-3.html">拼多多资源</a></li>
<li class="quietlee_67c6a_1e7ce"><a title="其它资源" href="https://new.asjzyw.com/category-4.html">其它资源</a></li>
</ul>
</section><section class="widget wow fadeInDown quietlee_7b5b1_50c4c" id="divTags">
<h3 class="widget-title"><i class="fa fa-divTags"></i><span>标签列表</span></h3>
<ul class="widget-box divTags"><li class="quietlee_642e9_2efb7">
<a href="https://new.asjzyw.com/tags-5.html" title="拼多多砍价">拼多多砍价<span class="tag-count">63</span></a>
</li><li class="quietlee_f457c_545a9">
<a href="https://new.asjzyw.com/tags-186.html" title="拼多多">拼多多<span class="tag-count">59</span></a>
</li><li class="quietlee_c0c7c_76d30">
<a href="https://new.asjzyw.com/tags-46.html" title="拼多多开店">拼多多开店<span class="tag-count">32</span></a>
</li><li class="quietlee_28380_23a77">
<a href="https://new.asjzyw.com/tags-33.html" title="抖音运营">抖音运营<span class="tag-count">26</span></a>
</li><li class="quietlee_9a115_8154d">
<a href="https://new.asjzyw.com/tags-97.html" title="抖音橱窗">抖音橱窗<span class="tag-count">25</span></a>
</li><li class="quietlee_d82c8_d1619">
<a href="https://new.asjzyw.com/tags-254.html" title="拼多多退店">拼多多退店<span class="tag-count">24</span></a>
</li><li class="quietlee_a684e_ceee7">
<a href="https://new.asjzyw.com/tags-152.html" title="抖音小店">抖音小店<span class="tag-count">23</span></a>
</li><li class="quietlee_b53b3_a3d6a">
<a href="https://new.asjzyw.com/tags-315.html" title="抖音代运营">抖音代运营<span class="tag-count">23</span></a>
</li><li class="quietlee_9f614_08e3a">
<a href="https://new.asjzyw.com/tags-143.html" title="抖音">抖音<span class="tag-count">19</span></a>
</li><li class="quietlee_72b32_a1f75">
<a href="https://new.asjzyw.com/tags-577.html" title="抖音播放量">抖音播放量<span class="tag-count">19</span></a>
</li><li class="quietlee_66f04_1e16a">
<a href="https://new.asjzyw.com/tags-49.html" title="西瓜视频">西瓜视频<span class="tag-count">18</span></a>
</li><li class="quietlee_093f6_5e080">
<a href="https://new.asjzyw.com/tags-292.html" title="拼多多商家">拼多多商家<span class="tag-count">17</span></a>
</li><li class="quietlee_072b0_30ba1">
<a href="https://new.asjzyw.com/tags-50.html" title="抖音商品橱窗">抖音商品橱窗<span class="tag-count">16</span></a>
</li><li class="quietlee_7f39f_8317f">
<a href="https://new.asjzyw.com/tags-477.html" title="抖音直播">抖音直播<span class="tag-count">16</span></a>
</li><li class="quietlee_44f68_3a841">
<a href="https://new.asjzyw.com/tags-79.html" title="抖音带货">抖音带货<span class="tag-count">14</span></a>
</li><li class="quietlee_03afd_bd66e">
<a href="https://new.asjzyw.com/tags-178.html" title="快手">快手<span class="tag-count">13</span></a>
</li><li class="quietlee_ea5d2_f1c46">
<a href="https://new.asjzyw.com/tags-134.html" title="小红书">小红书<span class="tag-count">12</span></a>
</li><li class="quietlee_fc490_ca45c">
<a href="https://new.asjzyw.com/tags-181.html" title="抖音粉丝">抖音粉丝<span class="tag-count">12</span></a>
</li></ul>
</section><section class="widget wow fadeInDown quietlee_baa86_8e62e" id="divComments">
<h3 class="widget-title"><i class="fa fa-divComments"></i><span>最新留言</span></h3>
<ul class="widget-box divComments"></ul>
</section> </aside>
</div>
<div class="listree-box quietlee_c4ee3_f1d71">
<h3 class="listree-titles"><a class="listree-btn" title="展开">目录[+]</a></h3>
<ul id="listree-ol" style="display:none;"></ul>
</div>
<div class="hidebody quietlee_4a71f_03ecf"></div>
<div class="showbody quietlee_96e2d_351ca">
<a class="showbody_c" href="javascript:void(0)" onclick="reward()" title="关闭"><img src="https://new.asjzyw.com/zb_users/theme/quietlee/style/images/close.png" alt="取消" /></a>
<div class="reward_img quietlee_02d18_fa8b2"><img class="alipay_qrcode" src="https://new.asjzyw.com/zb_users/theme/quietlee/style/images/wxcode.jpg" alt="微信二维码" /></div>
<div class="reward_bg quietlee_3017e_a6799">
<div class="pay_box choice quietlee_88941_f0147" data-id="https://new.asjzyw.com/zb_users/theme/quietlee/style/images/wxcode.jpg">
<span class="pay_box_span"></span><span class="qr_code"><img src="https://new.asjzyw.com/zb_users/theme/quietlee/style/images/wechat.svg" alt="微信二维码" /></span>
</div>
<div class="pay_box quietlee_0e514_bd36d" data-id="https://new.asjzyw.com/zb_users/theme/quietlee/style/images/alipay.jpg">
<span class="pay_box_span"></span><span class="qr_code"><img src="https://new.asjzyw.com/zb_users/theme/quietlee/style/images/alipay.svg" alt="支付宝二维码" /></span>
</div>
</div>
</div>
<script>
$(function(){
$(".pay_box").click(function(){
$(this).addClass('choice').siblings('.pay_box').removeClass('choice');
var dataid=$(this).attr('data-id');
$(".reward_img img").attr("src",dataid);
});
$(".hidebody").click(function(){
reward();
});
});
function reward(){
$(".hidebody").fadeToggle();
$(".showbody").fadeToggle();
}
</script><script>//分享代码
function Share(pType){
var pTitle = "想保存无水印短视频?这个方法让你轻松搞定"; //待分享的标题
var pImage = "https://new.asjzyw.com/zb_users/upload/2025/05/1738764737933_0.png"; //待分享的图片
var pContent = "浏览某个短视频网站时,常常会遇到想保存的视频不能下载,或者下载后带有水印的问题,这确实挺让人烦恼。实际上,我们可以编写一个程序来去除水印并下载视频,下面我会..."; //待分享的内容
var pUrl = window.location.href; //当前的url地址
var pObj = jQuery("div[class='yogo_hc']").find("h4");
if(pObj.length){ pTitle = pObj.text();}
var pObj = jQuery("div[class='yogo_hcs']").find("em");
if(pObj.length){ pContent = pObj.text(); }
var pObj = jQuery("div[class='con_cons']").find("img");
if(pObj.length){ pImage = jQuery("div[class='con_cons']").find("img",0).attr("src"); }
shareys(pType, pUrl, pTitle,pImage, pContent);
}
function shareys(a, c, b, e, d) {
switch (a) {
case "sina":
c = "//service.weibo.com/share/share.php?title\x3d" + encodeURIComponent("\u300c" + b + "\u300d" + d + "\u9605\u8bfb\u8be6\u60c5" + c) + "\x26pic\x3d" + e +"&appkey=&searchPic=true";
window.open(c);
break;
case "tqq":
c = "//connect.qq.com/widget/shareqq/index.html?url\x3d" + encodeURIComponent(c) + "\x26title\x3d" + encodeURIComponent(b) + "\x26pics\x3d" + e;
window.open(c);
break;
case "qzone":
c = "//sns.qzone.qq.com/cgi-bin/qzshare/cgi_qzshare_onekey?url\x3d" + encodeURIComponent(c) + "\x26title\x3d" + encodeURIComponent(b) + "\x26site\x3d\x26pics\x3d" + encodeURIComponent(e) + "\x26desc\x3d" + encodeURIComponent(d) + "\x26summary\x3d" + encodeURIComponent(d);
window.open(c)
}
};
</script><script src="https://new.asjzyw.com/zb_users/theme/quietlee/plugin/js/html2canvas.min.js"></script>
<script src="https://new.asjzyw.com/zb_users/theme/quietlee/plugin/js/common.js"></script>
<script>
var poster_open = 'on';
var txt1 = '长按识别二维码查看详情';
var txt2 = '新资源咨询网';
var comiis_poster_start_wlat = 0;
var comiis_rlmenu = 1;
var comiis_nvscroll = 0;
var comiis_poster_time_baxt;
$(document).ready(function(){
$(document).on('click', '.comiis_poster_a', function(e) {
show_comiis_poster_ykzn();
});
});
function comiis_poster_rrwz(){
setTimeout(function(){
html2canvas(document.querySelector(".comiis_poster_box_img"), {scale:2,useCORS:true}).then(canvas => {
var img = canvas.toDataURL("image/jpeg", .9);
document.getElementById('comiis_poster_images').src = img;
$('.comiis_poster_load').hide();
$('.comiis_poster_imgshow').show();
});
}, 100);
}
function show_comiis_poster_ykzn(){
if(comiis_poster_start_wlat == 0){
comiis_poster_start_wlat = 1;
popup.open('<img src="https://new.asjzyw.com/zb_users/theme/quietlee/plugin/img/imageloading.gif" class="comiis_loading">');
var url = window.location.href.split('#')[0];
url = encodeURIComponent(url);
var html = '<div id="comiis_poster_box" class="comiis_poster_nchxd quietlee_3e10a_ac9fb">\n' +
'<div class="comiis_poster_box quietlee_2651f_6bd09">\n' +
'<div class="comiis_poster_okimg quietlee_18a44_941b4">\n' +
'<div style="padding:150px 0;" class="comiis_poster_load quietlee_3bec4_a68dd">\n' +
'<div class="loading_color quietlee_1b5da_f25a2">\n' +
' <span class="loading_color1"></span>\n' +
' <span class="loading_color2"></span>\n' +
' <span class="loading_color3"></span>\n' +
' <span class="loading_color4"></span>\n' +
' <span class="loading_color5"></span>\n' +
' <span class="loading_color6"></span>\n' +
' <span class="loading_color7"></span>\n' +
'</div>\n' +
'<div class="comiis_poster_oktit quietlee_59188_ee190">正在生成海报, 请稍候</div>\n' +
'</div>\n' +
'<div class="comiis_poster_imgshow quietlee_71cd1_2b9de" style="display:none">\n' +
'<img src="" class="vm" id="comiis_poster_images">\n' +
'<div class="comiis_poster_oktit quietlee_3295c_76acb">↑长按上图保存图片分享</div>\n' +
'</div>\n' +
'</div>\n' +
'<div class="comiis_poster_okclose quietlee_0f418_0bc87"><a href="javascript:;" class="comiis_poster_closekey"><img src="https://new.asjzyw.com/zb_users/theme/quietlee/plugin/img/poster_okclose.png" class="vm"></a></div>\n' +
'</div>\n' +
'<div class="comiis_poster_box_img quietlee_871f7_8631f">\n' +
'<div class="comiis_poster_img quietlee_3cec1_54b0f"><div class="img_time quietlee_92616_ced57">05<span>2025/02</span></div><img src="https://new.asjzyw.com/zb_users/upload/2025/05/1738764737933_0.png" class="vm" id="comiis_poster_image"></div>\n' +
'<div class="comiis_poster_tita quietlee_3ee35_8903f">想保存无水印短视频?这个方法让你轻松搞定</div>\n' +
'<div class="comiis_poster_txta quietlee_751ec_b7fa6">浏览某个短视频网站时,常常会遇到想保存的视频不能下载,或者下载后带有水印的问题,这确实挺让...</div><div class="comiis_poster_x guig quietlee_5be8c_56f92"></div>\n' +
'<div class="comiis_poster_foot quietlee_cf3a8_e48ed">\n' +
'<img src="https://new.asjzyw.com/zb_users/theme/quietlee/plugin/api.php?url='+url+'" class="kmewm fqpl vm">\n' +
'<img src="https://new.asjzyw.com/zb_users/theme/quietlee/plugin/img/poster_zw.png" class="kmzw vm"><span class="kmzwtip">'+txt1+'<br>'+txt2+'</span>\n' +
'</div>\n' +
'</div>\n' +
'</div>';
if(html.indexOf("comiis_poster") >= 0){
comiis_poster_time_baxt = setTimeout(function(){
comiis_poster_rrwz();
}, 5000);
$('body').append(html);
$('#comiis_poster_image').on('load',function(){
clearTimeout(comiis_poster_time_baxt);
comiis_poster_rrwz();
});
popup.close();
setTimeout(function() {
$('.comiis_poster_box').addClass("comiis_poster_box_show");
$('.comiis_poster_closekey').off().on('click', function(e) {
$('.comiis_poster_box').removeClass("comiis_poster_box_show").on('webkitTransitionEnd transitionend', function() {
$('#comiis_poster_box').remove();
comiis_poster_start_wlat = 0;
});
return false;
});
}, 60);
}
}
}
var new_comiis_user_share, is_comiis_user_share = 0;
var as = navigator.appVersion.toLowerCase(), isqws = 0;
if (as.match(/MicroMessenger/i) == "micromessenger" || as.match(/qq\//i) == "qq/") {
isqws = 1;
}
if(isqws == 1){
if(typeof comiis_user_share === 'function'){
new_comiis_user_share = comiis_user_share;
is_comiis_user_share = 1;
}
var comiis_user_share = function(){
if(is_comiis_user_share == 1){
isusershare = 0;
new_comiis_user_share();
if(isusershare == 1){
return false;
}
}
isusershare = 1;
show_comiis_poster_ykzn();
return false;
}
}
</script>
</main>
<footer class="site-footer footer quietlee_e4ace_cf7d5">
<div class="site-info clearfix quietlee_505f1_d86b0">
<div class="container quietlee_a6528_0767c">
<div class="footer-left quietlee_9d5cf_d14af"><!--底部左边-->
<div class="footer-l-top clearfix quietlee_42db8_f1351">
<a rel="nofollow" href="https://m.asjzyw.com" target="_blank">网红笔记</a> </div>
<div class="footer-l-btm quietlee_dd1fc_21c7f">
<p class="top-text quietlee_f3a11_d87c1">安全运行<span id="iday"></span>天 <script>function siteRun(d){var nowD=new Date();return parseInt((nowD.getTime()-Date.parse(d))/24/60/60/1000)} document.getElementById("iday").innerHTML=siteRun("2008/08/08");</script></p>
<p class="jubao quietlee_29a12_60018">本站采用创作共用版权 <a href="http://creativecommons.org/licenses/by-nc-sa/3.0/cn/" target="_blank" rel="nofollow">CC BY-NC-SA 3.0 CN</a> 许可协议,转载或复制请注明出处</p>
<p class="btm-text quietlee_fe0da_707e0"><a class="ico-ico" href="http://beian.miit.gov.cn" rel="nofollow" target="_blank" rel="nofollow" title="京ICP备11000001号"><img src="https://new.asjzyw.com/zb_users/theme/quietlee/style/images/icp.png" alt="京ICP备11000001号">京ICP备11000001号</a><a class="beian-ico" target="_blank" href="/" rel="nofollow" title="京公网安备11000000000001号"><img src="https://new.asjzyw.com/zb_users/theme/quietlee/style/images/beian.png" alt="京公网安备11000000000001号">京公网安备11000000000001号</a> <span class="rt-times">运行时长:0.107秒</span><span class="rt-sql">查询信息:15 次</span></p>
</div>
</div>
<div class="footer-right quietlee_d67c0_95df6"><!--底部右边-->
<div class="wxcode quietlee_7e8da_9e6a5"><img alt="微信扫一扫" src="https://new.asjzyw.com/zb_users/theme/quietlee/style/images/wxcode_b.png"></div>
</div> </div>
</div>
<div id="backtop" class="backtop quietlee_af888_2562e">
<div class="bt-box top quietlee_e07b3_78725"><i class="fa fa-angle-up fa-2x"></i></div>
<div class="bt-box bottom quietlee_c20f8_c174d"><i class="fa fa-angle-down fa-2x"></i></div>
</div>
<script src="https://new.asjzyw.com/zb_users/theme/quietlee/script/jquery.pjax.js"></script>
<script src="https://new.asjzyw.com/zb_users/theme/quietlee/script/custom.js?v=2024-12-16"></script>
<script src="https://new.asjzyw.com/zb_users/theme/quietlee/script/jquery.lazy.js"></script>
<script src="https://new.asjzyw.com/zb_users/theme/quietlee/script/wow.min.js"></script>
<script src="https://new.asjzyw.com/zb_users/theme/quietlee/script/fancybox.js"></script>
</footer></body>
</html><!--108.81 ms , 15 queries , 3641kb memory , 0 error-->