
如今,网络世界里,大家普遍希望能找到无水印的高质量图片。但在小红书上,那些直接分享的图片却都带着水印,确实挺让人头疼。下面,咱们一起来详细了解如何解决这一难题。
小红书图片保存现状
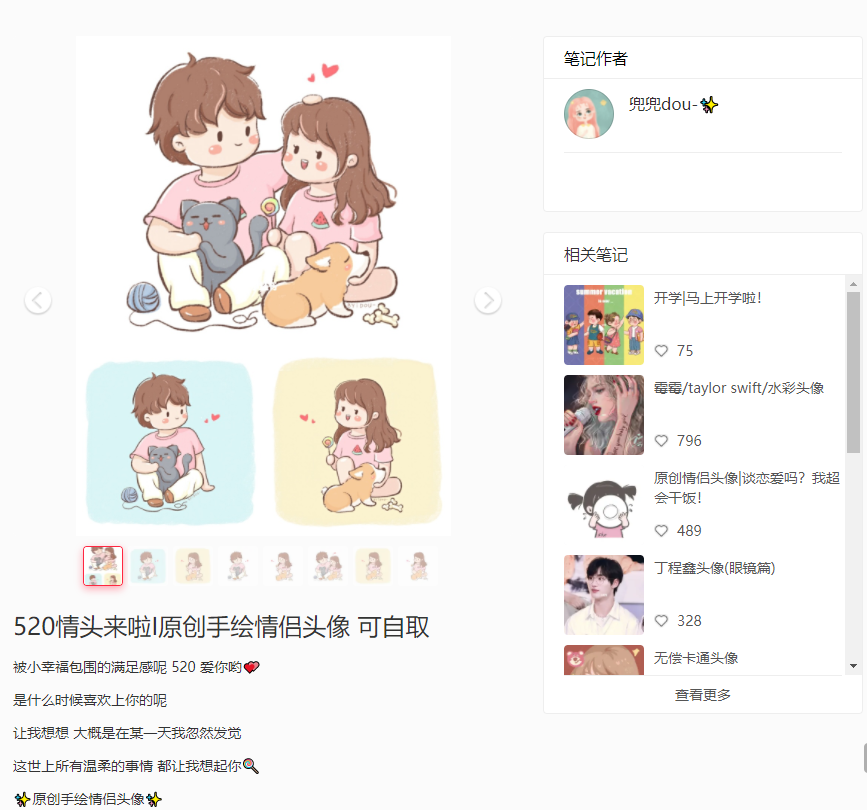
许多人想保存小红书的图片,可操作时却遇到难题。比如,通过复制分享链接在浏览器打开,虽然能保存图片,但图片上会有水印,这在很多情况下都不太方便。有些人为了得到无水印的图片,尝试了各种简单方法,比如寻找特定按钮,但往往都以失败告终。而且这种情况并不少见,许多用户都遇到了这样的麻烦。
了解通过分析请求头等途径能获取信息后,我们或许会想要探索一些非传统的手段。在挖掘分析图片数据的过程中,我们遭遇了不少困难,各种设备和网络状况都可能成为干扰。
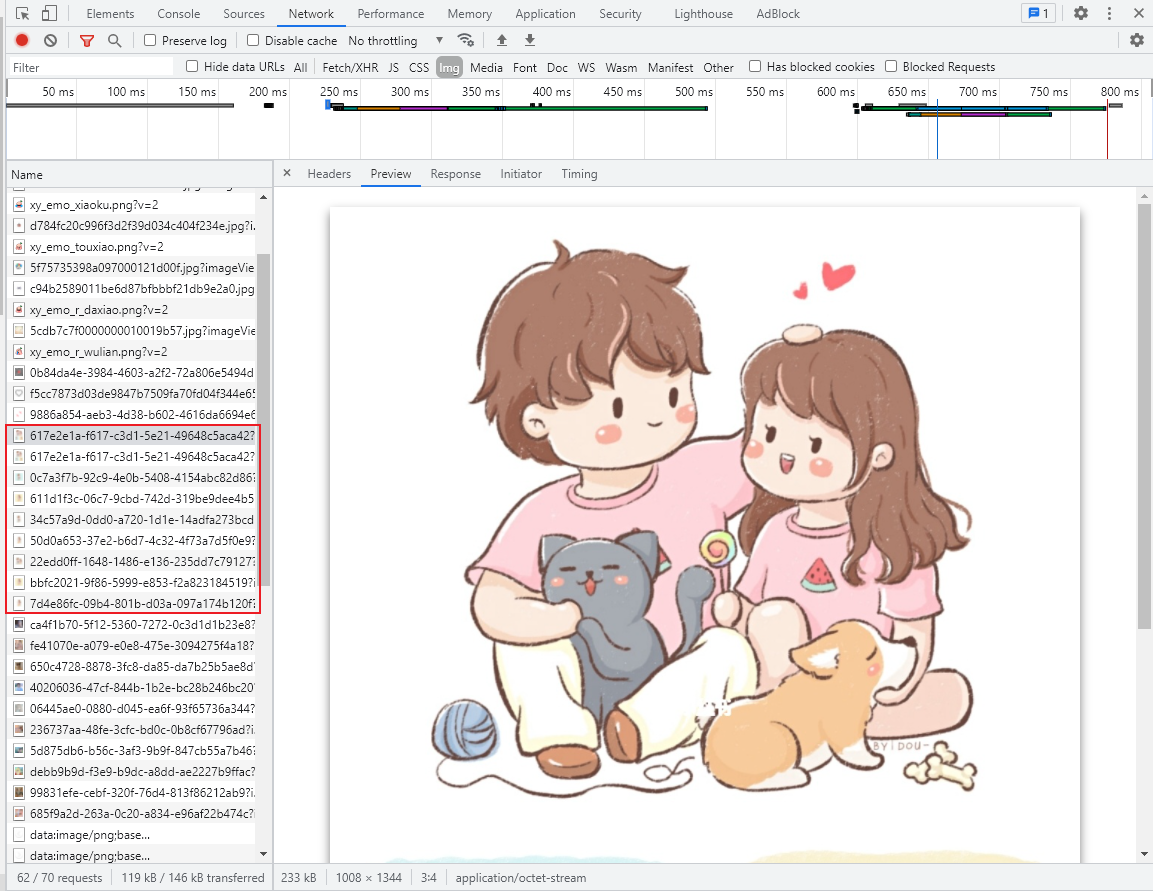
图片链接组成分析
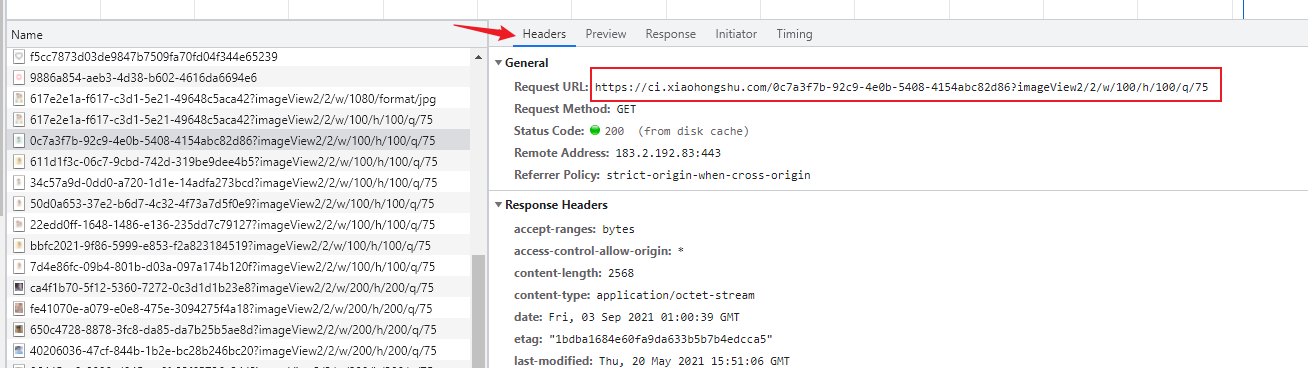
图片的链接通常包含域名、标识符和文件压缩类型。我们特别关注的是压缩类型这一部分,因为它主要影响图片的大小和清晰度,而与水印的有无无关。有时候,即使去掉这一部分,也能找到原始图片。这一发现对于我们深入探究如何获取无水印图片具有重要意义。
在实践操作中,我们对比了带有水印的图片的各个部分。经过众多测试,我们确认这种压缩格式的稳定性极高。同时,不同种类的图片在这方面的变化并不显著。由此可见,图片的核心信息,如水印的有无,与这一字段的关系并不紧密。

水印与ID的关联推测
用户常有这样的感觉:无水印图片的标识符或许与带水印的图片标识符有关联。这主要是因为在图片系统中,标识符在很大程度上影响着图片的识别度。因此,我们可以尝试将带水印图片的URL中的图片标识符替换成追踪标识符的值,进而尝试获取无水印图片。
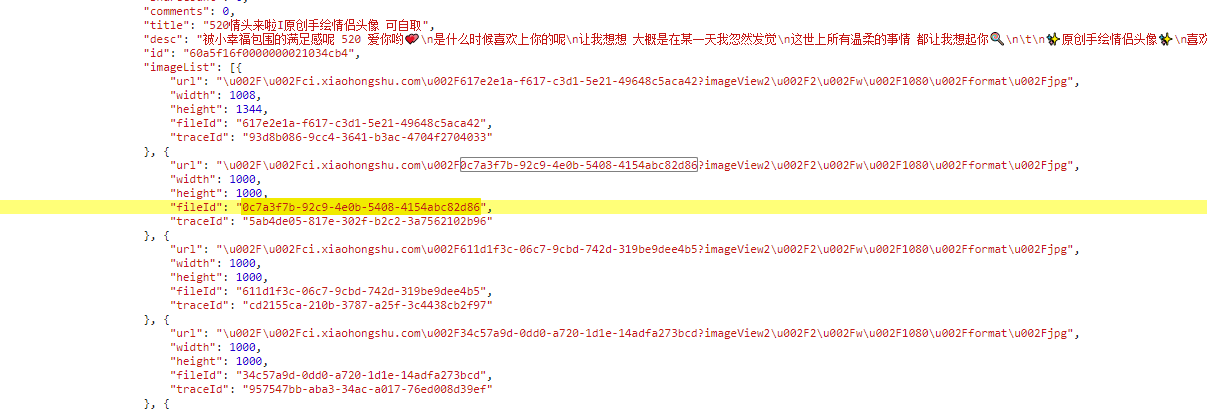
经过多次实验,我们发现这种联系或许确实存在。这并非无端的臆测,而是基于对网络图片储存机制的基础认识,以及对小红书平台图片管理方式的预测。这一推理过程,其实是一个不断探索的过程。
获取网页源码提取信息

要解决这一问题,需从源头开始,即分析小红书分享链接的网页源代码。在源代码中,需寻找名为imageList的关键字段,它承载着图片的相关信息。将此字段转换成json格式,然后从中提取出traceId字段。这一步骤要求对网页开发有所了解,并掌握基本的代码解析技巧。
进行此类操作通常需要借助特定工具或代码库。无论是掌握对JSON格式的基本操作,还是深入理解imageList字段在网络请求中的具体作用,这对众多非专业人士来说都构成了一定的难题。
import requests

def fetchUrl(url):
'''
发起网络请求,获取网页源码
'''
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9 ',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 UBrowser/6.2.4098.3 Safari/537.36',
'cookie':'你自己的 cookie',
}
r = requests.get(url, headers = headers)
return r.text发起网络请求的要点
在用requests库进行网络请求时,我们需指定目标网址,即url。headers部分则扮演着重要角色,它能使爬虫模拟浏览器行为,向服务器传递所需参数。特别地,小红书的服务器还会检查cookie的有效性。
若cookie未填写或已过期,访问便会受阻。这时,需将浏览器内的cookie复制后,替换进代码里。特别要留意这一细致的操作步骤。不少网络请求失败的情况,往往源于这些小细节处理不当,例如cookie设置不当或对服务器验证机制理解有误等。
def parsing_link(html):
'''
解析html文本,提取无水印图片的 url
'''
beginPos = html.find('imageList') + 11
endPos = html.find(',"cover"')
imageList = eval(html[beginPos: endPos])
for i in imageList:
picUrl = f"https://ci.xiaohongshu.com/{i['traceId']}"
yield picUrl, i['traceId']
函数功能实现细节
存在特定函数,能解析网页源代码,从中提取去除水印的图片链接。比如,通过.find函数找到起始和结束位置,进而提取。这个过程看似容易,实则涉及诸多逻辑要点。此外,在下载图片链接并保存在本地时,也有不少注意事项。

处理网络请求结果并保存文件时,若采用r.content而非r.text,这并非常规做法。为何在保存文件时,mode需选择wb而非w?这其中的原因需要我们深入探究。特别是对于图片这类特殊资源,保存模式的差异可能会影响到图片的完整性等问题。
你也想解决图片带水印的问题,轻松保存小红书上的美图吗?欢迎在评论区发表你的见解。别忘了点赞和转发这篇文章。
def download(url, filename):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 UBrowser/6.2.4098.3 Safari/537.36',
}
with open(f'{filename}.jpg', 'wb') as v:
try:
r = requests.get(url, headers=headers)
v.write(r.content)
except Exception as e:
print('图片下载错误!')






