iPhone用户可能希望在小红书上轻松获取图片,却又不愿经历繁琐过程。这时,利用快捷指令和Python可以高效完成下载任务,这正是我们今天要向大家介绍的知识点。
一 iPhone快捷指令的初步应用
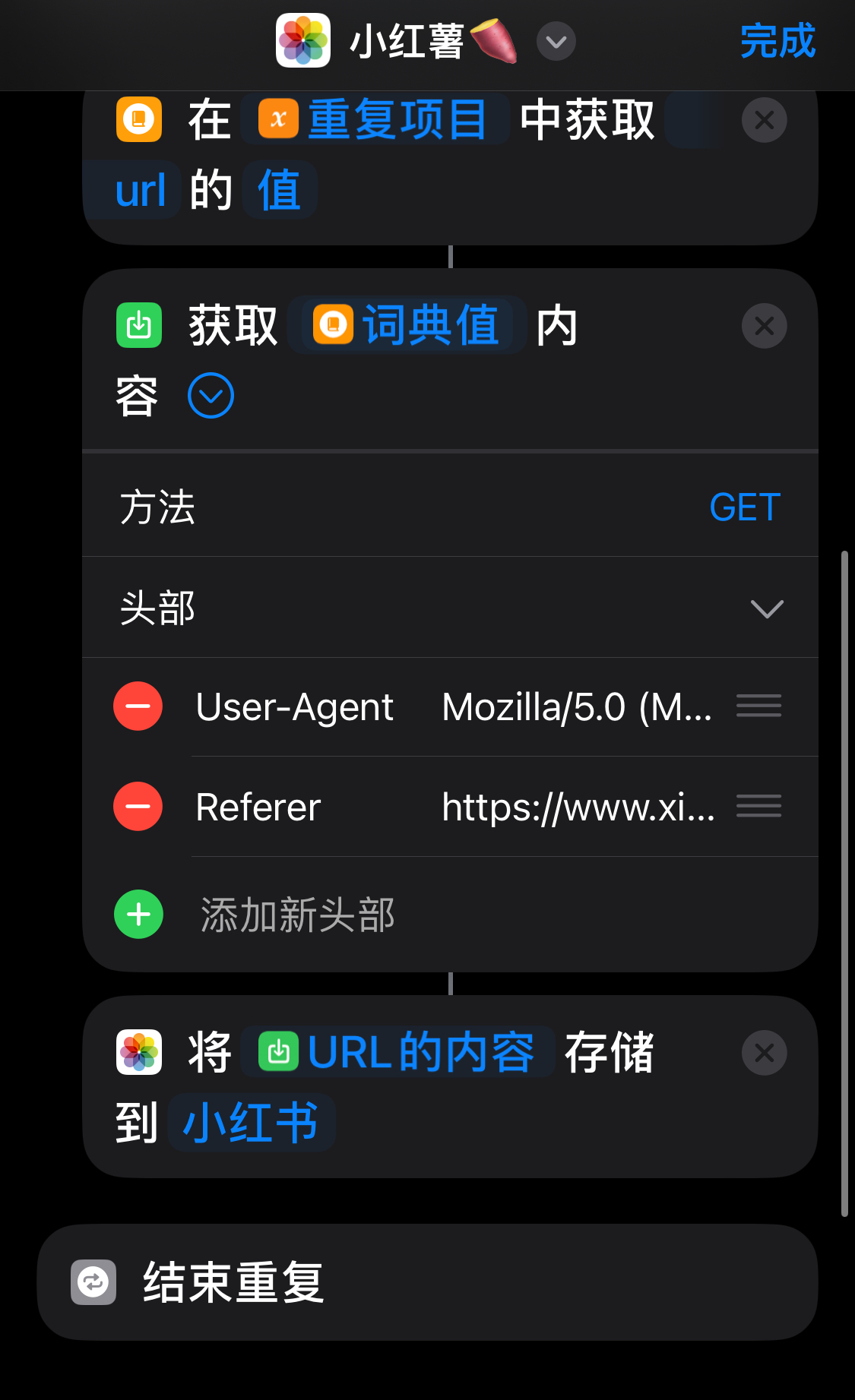
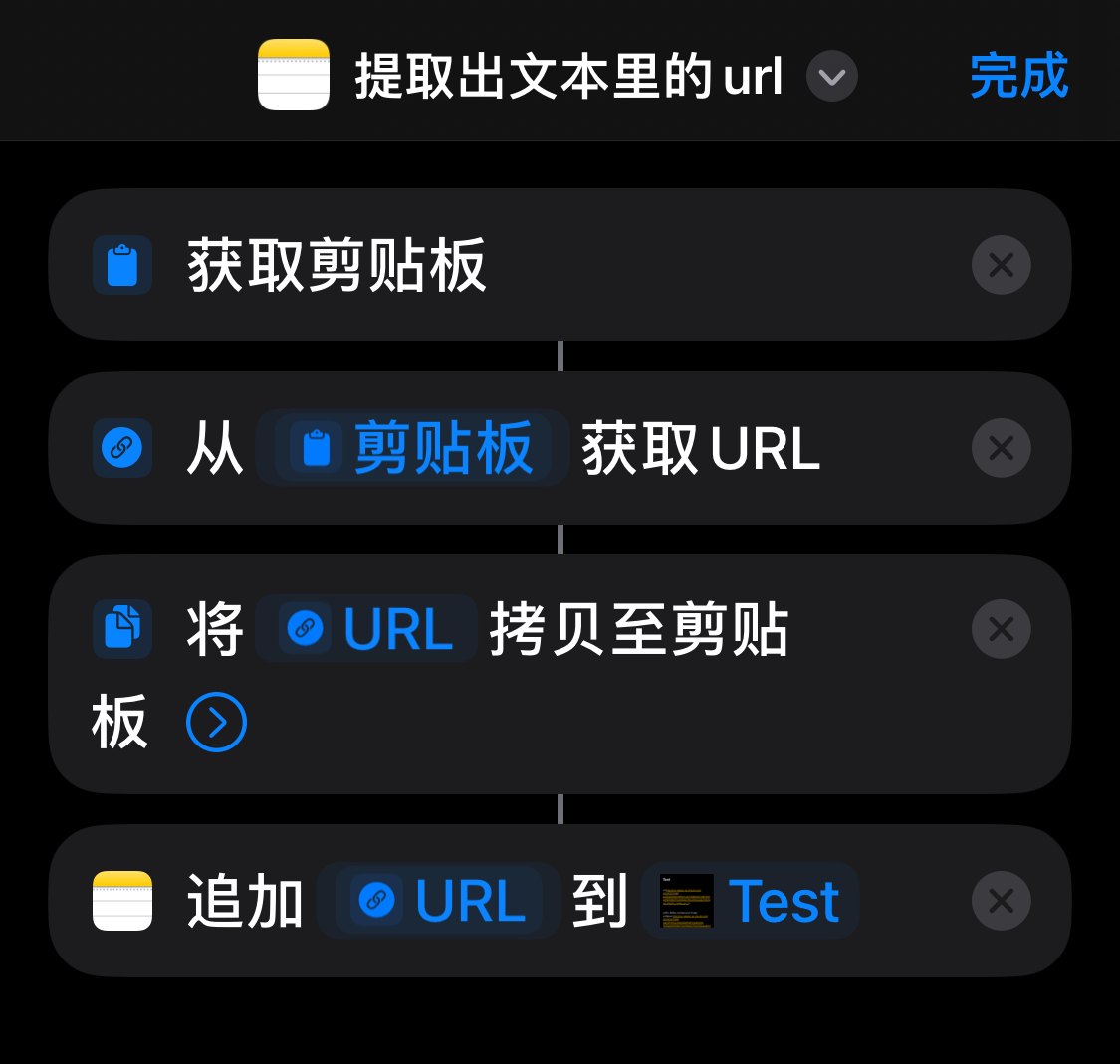
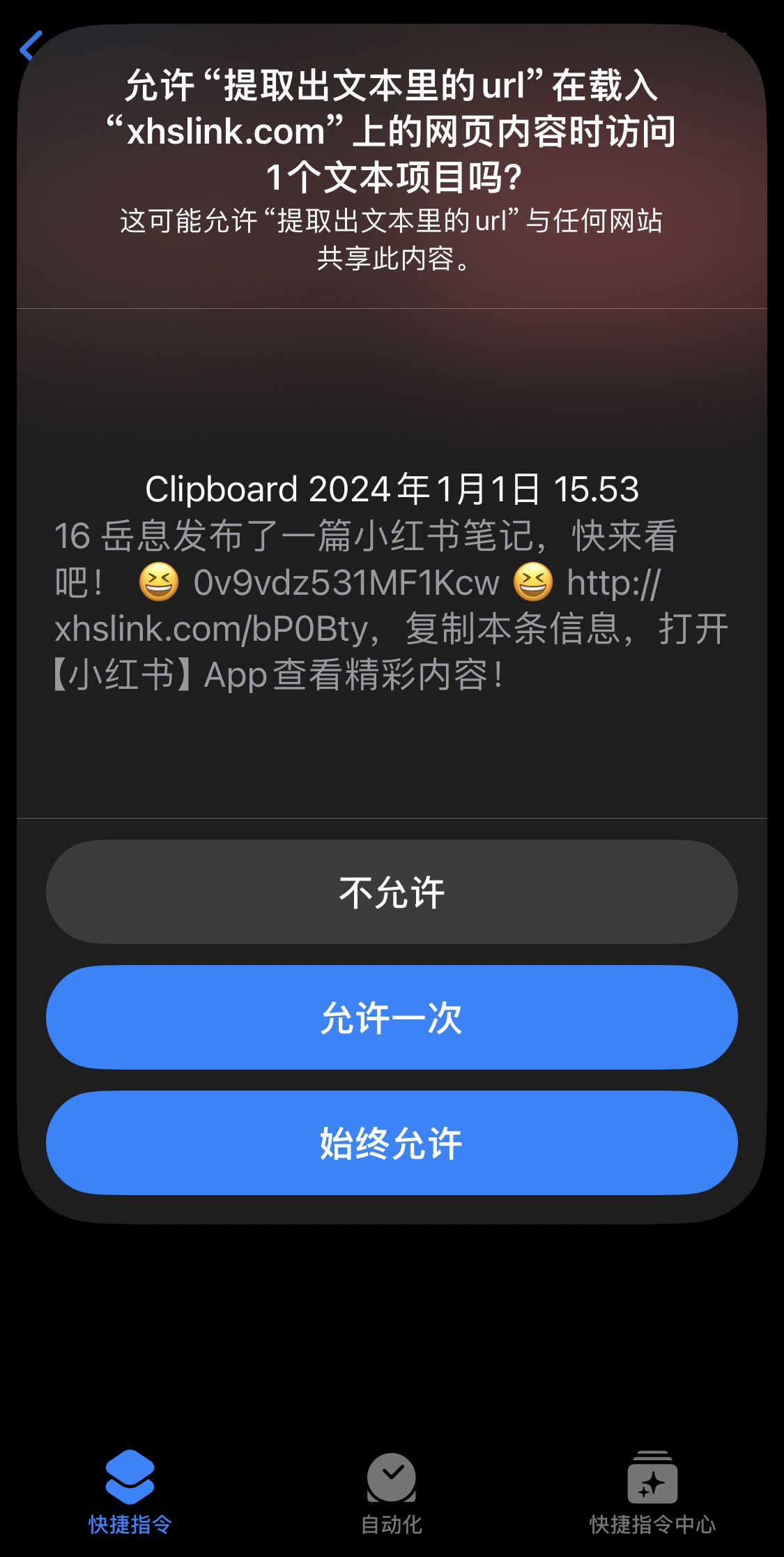
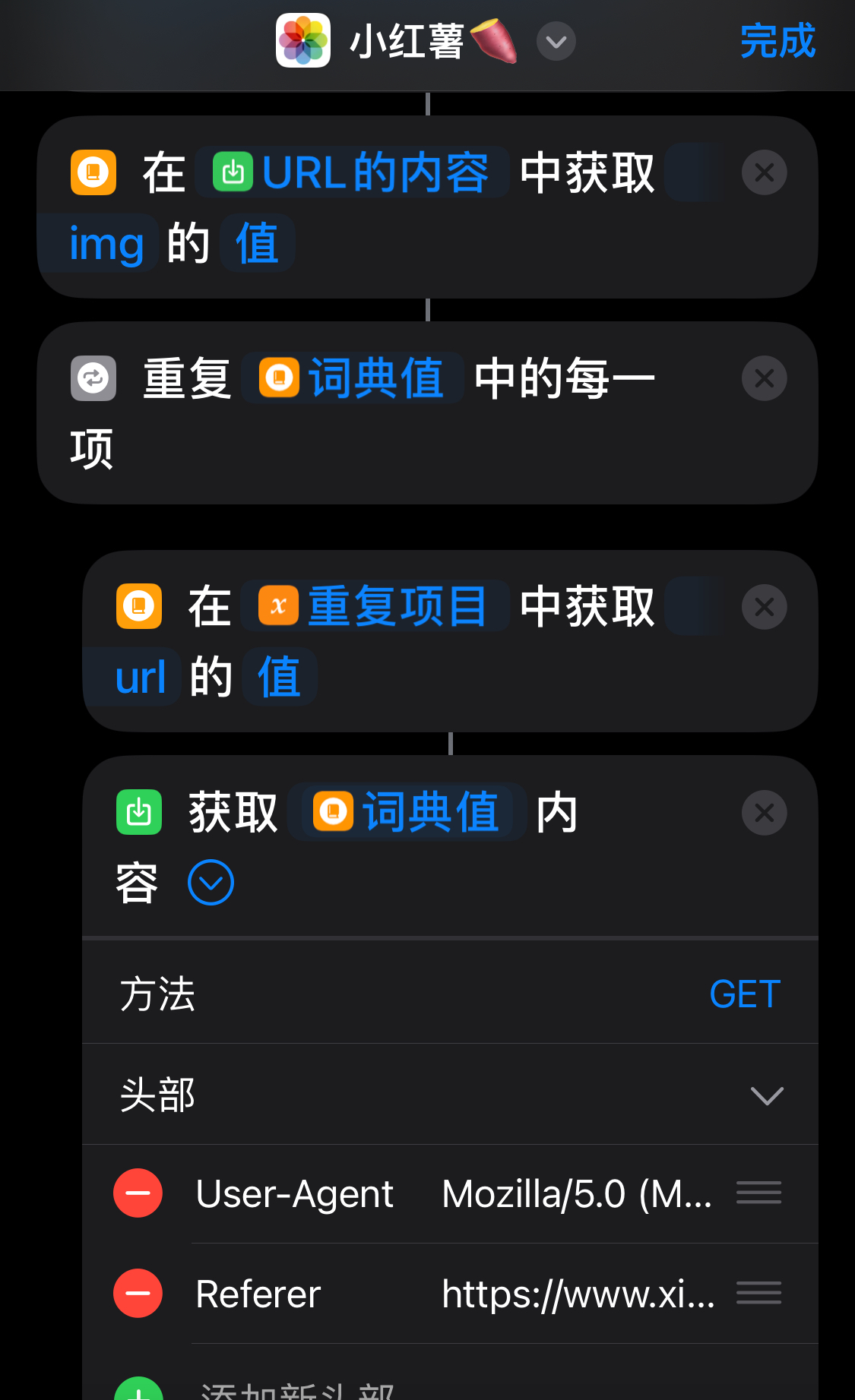
iPhone上,快捷指令功能强大。它能处理小红书的分享链接。我们复制链接后,快捷指令能提取出链接中的网址。这个网址就是小红书的网页链接。这个过程虽简单,却是操作的关键起点,引领我们进入下载环节。快捷指令通过简便操作,提取链接中的关键信息,为后续数据处理打下基础。
快捷指令提取网址的功能,在日常生活中非常实用。iPhone用户只需简单几步,就能初步获取信息。这种简便性,让许多想从小红书获取信息的人,轻松完成第一步,也为与电脑端协作提供了可能。
二 本地电脑的Python服务搭建
Python,这门功能全面的编程语言,在当前场景中扮演着关键角色。我们借助Python的Flask框架,在个人电脑上构建了一个服务。在这个过程中,我们得先选定一个端口来监听,例如文中提到的5001端口。这个端口相当于一个专门的入口,一旦被占用,我们也可以选择5000等其他端口作为替代。
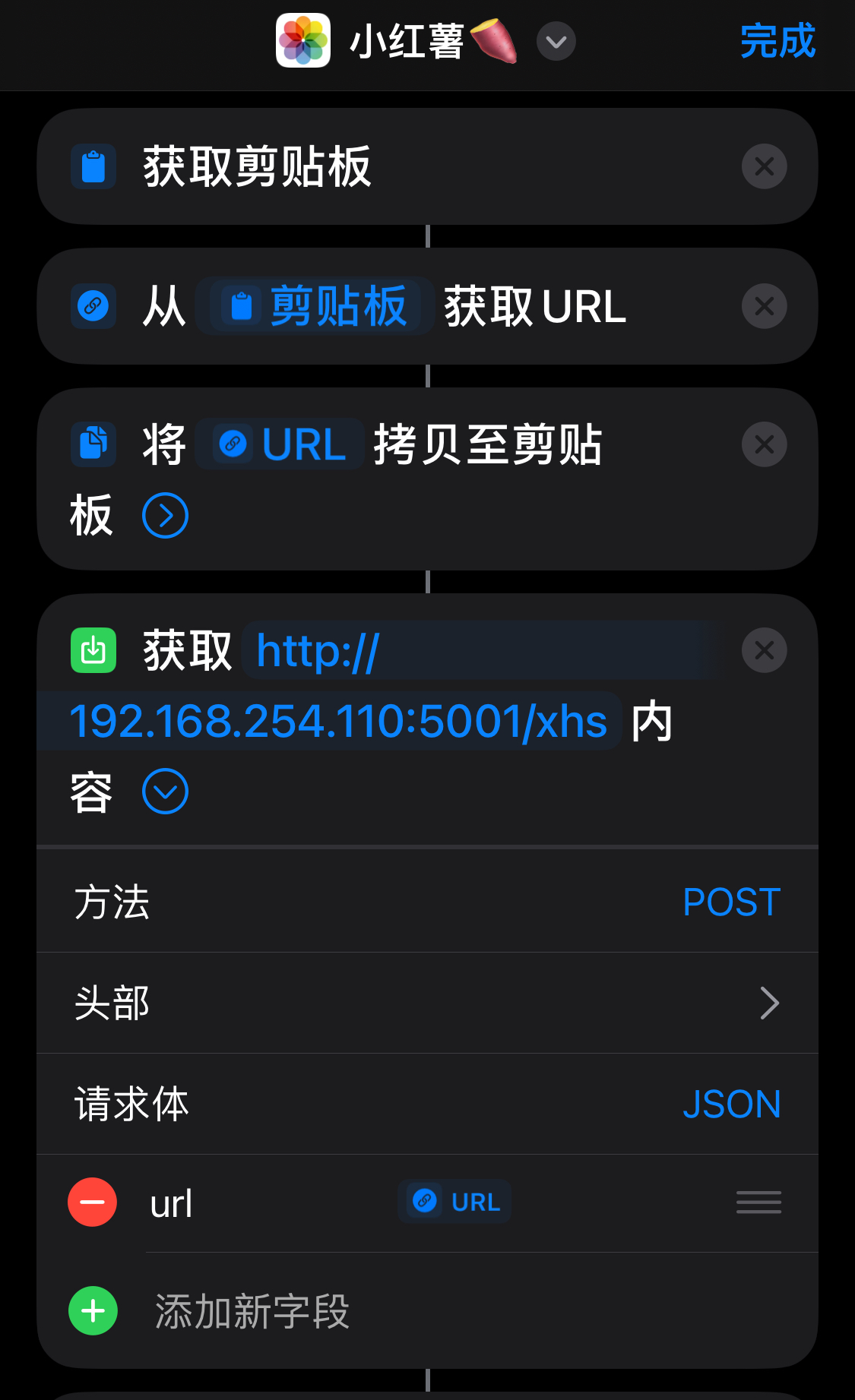
Flask框架构建的服务拥有独特的用途和价值。这样的服务运行在类似192.168.254.110:5001/xhs的地址。它主要负责接收POST请求,并从iPhone快捷指令获取URL信息。这种基于特定请求和地址的服务,在数据处理流程中扮演着关键的中转角色。
三 数据解析找寻图片链接
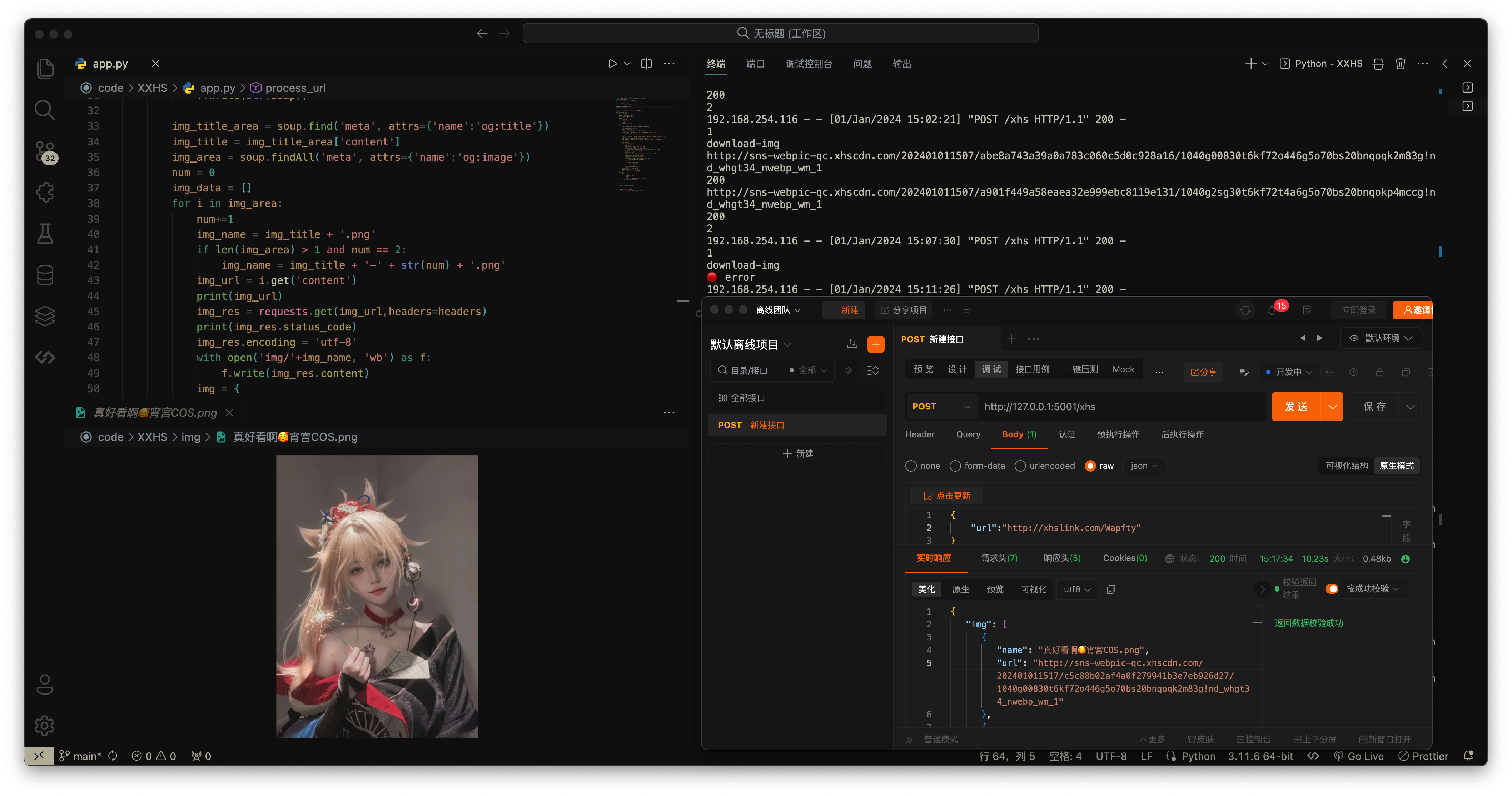
收到URL后,Python便施展其独特功能。它运用requests模块向链接发送请求,宛如派遣一名信使去搜集网页内容。随后,借助BeautifulSoup模块分析网页,这一过程如同在纷繁杂乱的信息中挖掘宝藏,而那宝藏正是图片的链接。
from flask import Flask, request, jsonify
app = Flask(__name__)
@app.route('/xhs', methods=['POST'])
def process_url():
# 获取JSON数据
data = request.json
url = data.get('url')
# 返回结果
return jsonify({'result': url})
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5001)
此过程借助Python强大的功能库进行精确分析。要成功完成这一任务,关键在于全面了解网页的构造和数据的存储模式。通过解析网页,找到图片的链接,这一环节为后续的下载任务提供了精确的网址,确保了整个过程的顺利进行。
四 下载方式选择
拿到图片链接后,我们有几种处理手段。比如,可以直接用电脑根据链接下载图片,这对电脑用户来说很方便。又或者,可以把链接传给手机上的快捷操作,手机就会帮忙下载。这样,手机用户也能方便地保存和使用图片了。

无论是从电脑下载还是移动到手机上下载,都展现了操作流程的便捷性。电脑端资源众多,处理能力出众;手机端下载则便于随时查阅和应用,两者各有所长。
五 基于POST请求的数据交互
在这个场景中,POST请求扮演着关键角色。与我们在浏览器中常用以访问IP地址的GET请求不同,POST请求是专门用于此类数据交换的。我们可以通过“postman”或“apipost”等工具来发送POST请求。
from flask import Flask, request, jsonify
import requests
from bs4 import BeautifulSoup

app = Flask(__name__)
headers = headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
'Referer': 'https://www.xiaohongshu.com/',
# 'Cookie':'' #必要时候带上Cookie
}
@app.route('/xhs', methods=['POST'])
def process_url():
# 获取JSON数据
data = request.json
url = data.get('url')
data = {
'status': 200,
'img':'',
'msg':''
} # 等等要返回的数据
try:
res = requests.get(url,headers=headers)
res.encoding = 'utf-8'
html = res.text
soup = BeautifulSoup(html, 'lxml')
# 可以把爬取的网页写下来看看真正爬取到的结构
with open('test.html', 'w', encoding='utf-8') as f:
f.write(str(soup))
# 获取图片名称
img_title_area = soup.find('meta', attrs={'name':'og:title'})
img_title = img_title_area['content']
# 获取图片链接
img_area = soup.findAll('meta', attrs={'name':'og:image'})
num = 0
img_data = []
for i in img_area:
# 给图片1号 2号.... 加一下后缀~
num+=1
img_name = img_title + '.png'
if len(img_area) > 1 and num == 2:
img_name = img_title + '-' + str(num) + '.png'
img_url = i.get('content')

### 【这一部分是本地下载,如果你只是想下载到手机,可以去掉这段】
try:
img_res = requests.get(img_url,headers=headers)
img_res.encoding = 'utf-8'
with open('img/'+img_name, 'wb') as f:
f.write(img_res.content)
except:
continue
### 【 这就是这7行.. 记得如果要使用,在当前目录新建一个叫 img 的文件夹哦】
##【下面就是整理一下数据~】
img = {
'name':img_name,
'url':img_url
}
img_data.append(img)
data['img'] = img_data
data['status'] = 200
data['msg'] = '✅ 获取成功'
except:
data = {
'status': 403,
'img': '',
'msg': '❌ 获取失败... 程序出错'
} # 等等要返回的数据
# 返回结果
return jsonify(data)
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5001)
POST请求使得iPhone快捷指令中的数据能以恰当的形式传输至电脑端的Python服务。这一请求的精确性与稳定性是数据传输成功的关键。在整个流程中,从手机到电脑再到手机,它扮演了至关重要的桥梁角色。
六 程序完善拓展
此程序仍有改进余地。不仅限于图片处理,还能开发下载视频的功能。甚至能识别不同网站的网页内容,例如抖音上的视频也适用此方法进行下载。这样的扩展功能使得该技术路径的应用范围更为广泛。
随着用户需求的持续增加,程序持续优化升级显得尤为重要。原本仅限于小红书图片下载的功能,现已拓展至多个平台和多种数据类型的下载,这显著提升了技术的实用性和吸引力。
你是否有意尝试此法来搜集心仪的小红书图片或其它平台资料?不妨在评论区发表意见,参与互动。若你觉得这篇文章对你有帮助,别忘了点赞和转发。